Why your existing playbook breaks
What you’ll learn: Name the four assumptions in traditional infrastructure planning that AI inference violates, and articulate the new reality each one is replaced by.
The traditional IT planning rhythm has worked for a decade because hardware scaling was predictable. If you needed to support more users, you added a standardized cluster node. Compute, memory, and I/O scaled in balanced, familiar ratios. If you added another rack of standard enterprise servers, you knew exactly how much application traffic it could safely absorb.
Inference breaks four of these foundational planning assumptions. Each one breaks quietly. The numbers look familiar on a spreadsheet, but if you plan against them the way you would plan a traditional web tier or database, you will either over-provision by four times or suffer catastrophic failures in production.
This module names each broken assumption, what replaces it, and highlights exactly where the infrastructure team and the AI workload owners must collaborate to survive.
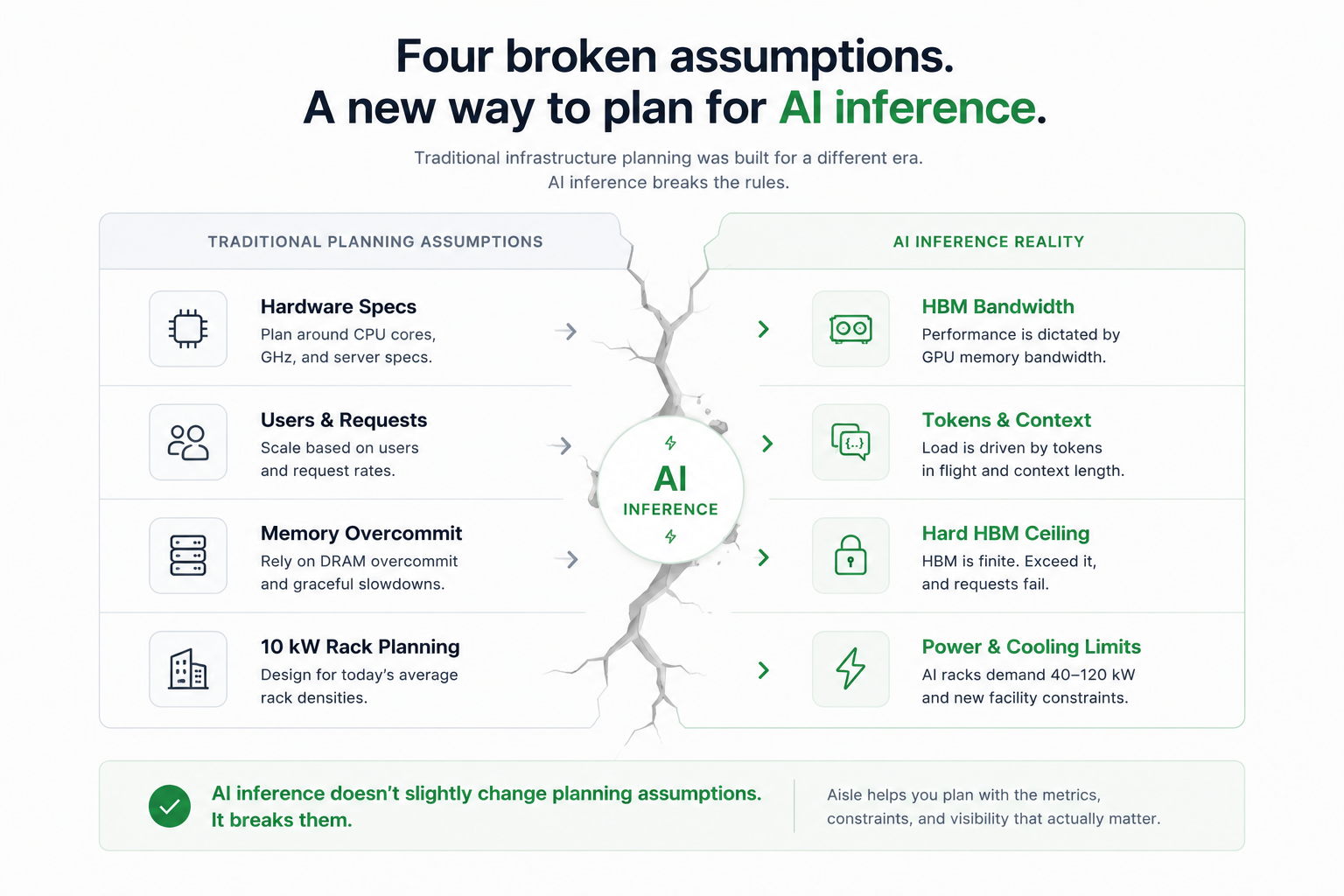
The four assumptions, side by side with what replaces them in an AI inference workload.
Assumption 1: You can plan using standard hardware spec sheets
Traditional planning relies on headline specs: CPU cores, clock speed, RAM capacity, and network bandwidth. For AI inference, these numbers hide the real constraint.
The critical metric for LLM generation is HBM (High Bandwidth Memory) bandwidth. Serving an LLM is a data-delivery bottleneck; the hardware spends far more time waiting to read model parameters from memory than it does processing math. For example, the NVIDIA H100 and H200 have nearly identical raw compute power, but the H200's 43% higher memory bandwidth unlocks 60% to 90% more token throughput.
Planning requires a new vocabulary:
- KV Cache Footprint: The high-speed memory eaten up just by holding a user's ongoing conversation history in VRAM (roughly 160 KB per token for a 70B model at FP8).
- Precision (Quantization): How heavily the model's math is compressed (e.g., FP16 down to FP8 or INT4), which instantly cuts your memory requirement in half or more.
Assumption 2: Sizing is driven entirely by user headcount and traffic rates
Traditional sizing asks two questions: How many users? and What is their request rate?
For inference, scaling by headcount is a trap. The defining metric is: "How many tokens are actively in flight at peak, and how long are the context histories?"
Imagine 500 users asking an AI short questions using a tight, 4,000-token context window. That is a light, easy-to-manage hardware footprint. Now, take those exact same 500 users and have them point the AI at massive documents using a 128,000-token context window. Your user count stayed exactly the same, but your infrastructure requirements just skyrocketed by an order of magnitude.
Assumption 3: Memory has a graceful degradation path (The Death of Overcommit)
In traditional virtualization, memory is fluid. If a database spikes, it safely spills over to system RAM or swaps to NVMe SSDs. Performance degrades, but the service stays alive. Because of this, IT teams routinely "overcommit" memory, assuming not everyone will max out at once.
AI inference has no graceful degradation, and overcommit is dead. The active working memory of an ongoing conversation (the KV cache) must live directly in HBM alongside the model weights. While inference engines can technically swap blocks back to system RAM under extreme pressure, doing so introduces massive PCIe bottlenecks that destroy your latency targets. If HBM fills up in production, requests don't just slow down—they fail outright. You must provision for hard, non-negotiable peak memory ceilings.
Assumption 4: Existing facilities can comfortably house the hardware
For a decade, data centers have handled a predictable envelope of 8 to 15 kilowatts (kW) per rack, which accommodates dense rows of CPU servers comfortably.
A single modern 8-GPU baseboard chassis (like an NVIDIA HGX H100 or H200) draws 10 to 11 kW all by itself. One server maxes out the allocation for an entire legacy rack. Attempting to stack four of these pushes 40 kW. Moving into cutting-edge architectures like a liquid-cooled Blackwell NVL72 rack means dealing with a massive 120 kW to 140 kW per rack footprint.
Furthermore, GPUs run at near-maximum thermal design power (TDP) continuously while serving heavy inference loads, rather than the bursty patterns of CPUs. This is a structural facilities conversation that must happen months before hardware lands on the loading dock.
The Blindspot: Why you can't plan infra in a silo
The underlying reality of these four broken assumptions is that infrastructure is no longer decoupled from code. In the AI era, a single engineering choice made by the data science team will completely rewrite your physical infrastructure requirements.
For example, if the AI team decides to run a massive model that cannot fit on a single GPU, they must split it using different parallelism approaches. If they choose Tensor Parallelism (splitting model layers across multiple GPUs), the system requires nearly instantaneous mathematical synchronization. Sizing a cluster with standard PCIe slots and regular network switches here will entirely cripple the application; Tensor Parallelism mandates ultra-fast intra-node fabric like NVLink or highly specialized backend networks like InfiniBand or RoCE. Conversely, if they opt for Pipeline Parallelism (splitting the model sequentially), the networking strain shifts entirely, changing your bottleneck to sequential memory caching and batch-scheduling configurations.
If you plan your networking, storage, and node layouts based purely on a passive hardware requisition form without understanding the data science team's software architectural roadmap, you are highly likely to build the wrong architecture.
The next four modules give you the explicit vocabulary to turn this friction into a competitive advantage. M3 explains what is actually happening inside a GPU during inference, M4 deconstructs the mechanics of the KV cache, M5 details the seven variables you must track, and M6 walks through a complete, real-world sizing calculation.
Try this in the SizerOpen the Sizer with the default 70B Llama RAG workload to see how changing context length completely resizes the physical hardware footprint.